MMLU-Pro est un nouveau benchmark d’évaluation des modèles de langage , conçu pour mesurer leurs compétences en compréhension, raisonnement et résolution de problèmes dans des contextes complexes. Il s’agit d’une version améliorée du benchmark MMLU (Massive Multitask Language Understanding) , largement utilisé pour évaluer les performances des grands modèles de langage.
Contrairement au MMLU original, MMLU-Pro propose des questions plus difficiles, avec davantage de choix possibles et une structure favorisant le raisonnement logique . Ce benchmark contient plus de 12 000 questions rigoureusement sélectionnées , provenant d’examens universitaires et de manuels académiques. Ces questions couvrent 14 domaines variés :
- Biologie
- Business / Économie
- Chimie
- Informatique
- Économie
- Ingénierie
- Santé
- Histoire
- Droit
- Mathématiques
- Philosophie
- Physique
- Psychologie
- Autres
Quelles sont les nouveautés de MMLU-Pro par rapport au MMLU classique ?
1. Augmentation du nombre d'options par question
- MMLU original : 4 options par question
- MMLU-Pro : 10 options par question
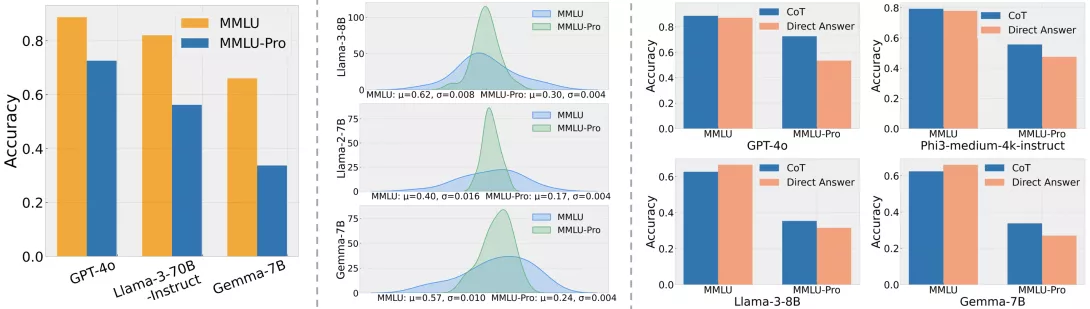
Cette augmentation rend l'évaluation beaucoup plus difficile , réduit drastiquement les chances de réussite par simple hasard (probabilité de 1/10 au lieu de 1/4), et oblige les modèles à raisonner correctement plutôt qu’à deviner.
2. Focus accru sur le raisonnement logique
- MMLU original : Questions principalement basées sur la connaissance pure , peu exigeantes en termes de raisonnement. Les méthodes comme PPL (Perplexité) fonctionnaient bien.
- MMLU-Pro : Intègre beaucoup plus de questions nécessitant un raisonnement structuré .
Résultat observé : les modèles utilisant des techniques de Chain-of-Thought (CoT) obtiennent jusqu'à 20 % de mieux que ceux se basant uniquement sur la perplexité (PPL). Cela montre que MMLU-Pro mesure effectivement la capacité de raisonnement des modèles.
3. Réduction de la sensibilité aux variations de prompt
- Grâce à l'augmentation du nombre de distracteurs (fausses réponses), la probabilité de réponse correcte par chance diminue fortement .
- Le benchmark a été testé avec 24 styles de prompts différents :
- Sur MMLU : variation de 4 à 5 % selon le style du prompt
- Sur MMLU-Pro : variation réduite à seulement 2 %
Cela montre que les résultats sont plus stables et fiables , ce qui renforce la robustesse du benchmark.
Objectif du Leaderboard
Le leaderboard vise à classer les modèles de langage selon leur performance sur le benchmark MMLU-Pro . Pour y apparaître, les soumissions doivent être accompagnées de preuves solides montrant que le système testé est bien un modèle de langage authentique , et non une solution ad hoc ou optimisée spécialement pour ce benchmark.
La vérification est stricte afin de garantir l’intégrité des résultats et leur comparabilité équitable entre les modèles.
Accès aux Ressources
Les ressources suivantes sont disponibles librement :
Dataset
Scripts d'évaluation
Article scientifique
Performances des Modèles
La page présente également un tableau des performances des différents modèles testés sur ce benchmark. Ces scores permettent de comparer objectivement leur capacité de compréhension, de raisonnement et de généralisation dans des domaines académiques variés.
Conclusion
MMLU-Pro représente une évolution significative par rapport au benchmark MMLU traditionnel :
- Plus de difficulté grâce à 10 options par question.
- Un meilleur équilibre entre connaissances et raisonnement .
- Une robustesse accrue face aux variations de prompt .
- Des résultats plus fiables et représentatifs des capacités réelles des modèles de langage.
C’est donc un outil précieux pour les chercheurs, développeurs et entreprises souhaitant mesurer précisément la qualité de leurs modèles d’IA générative dans des contextes académiques et professionnels.