Laboratoire d'Anthropologie des Savoirs Numériques & Ingénierie Éducative
Transformer la connaissance en récit, le récit en dialogue, et le dialogue en action
MDesigner.org accompagne les entreprises, institutions et organisations dans la conception de stratégies de Gestion Multimodale des Savoirs fondées sur la recherche.
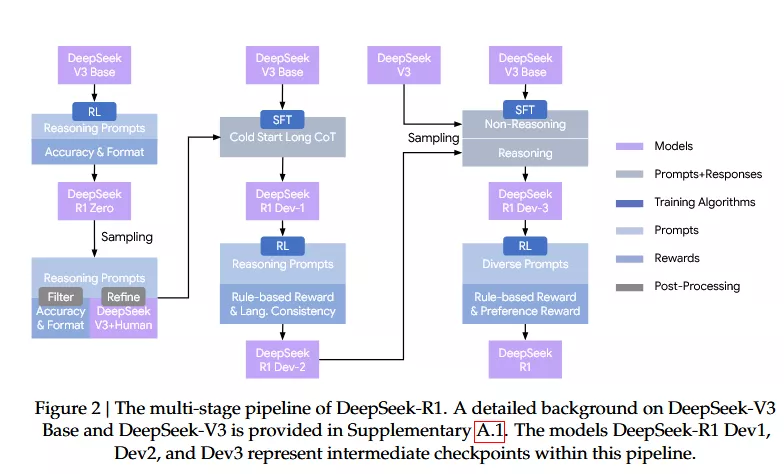
Pendant des années, DeepSeek a entraîné ses modèles de langage à imiter le raisonnement humain. En leur donnant des exemples, des démonstrations pas-à-pas, des "chaines de pensée" soigneusement annotées, cette approche qui fonctionnait... jusqu'à un certain point.Mais voici le paradoxe : en contraignant l'IA à penser comme nous, sa capacité à penser mieux que nous est limité. C'est le défi qu'a relevé l'équipe DeepSeek avec leur modèle R1 - et la solution est aussi élégante que contre-intuitive.
La Révolution : L'Apprentissage par Renforcement Pur
Imaginez apprendre à un enfant les mathématiques sans jamais lui montrer comment résoudre un problème. Juste en lui disant : "Voici l'énoncé, voici la réponse correcte. Trouve le chemin." Les chercheurs de DeepSeek ont abandonné les démonstrations humaines pour adopter une approche radicale : l'apprentissage par renforcement pur.
Le Secret ? Deux Simples Règles :
✅ Réponse correcte = +1 point
❌ Réponse incorrecte = 0 point
Rien sur la méthode. Rien sur l'élégance. Rien sur la clarté des explications. Seul le résultat final compte.
Le Piège Invisible : Pourquoi les Exemples Nuisent
Voici une découverte cruciale : donner des exemples de raisonnement à R1 dégrade ses performances. Pourquoi ? Parce qu'un exemple humain de 3-4 étapes devient un plafond invisible. Le modèle se sent contraint de rester dans ce cadre, alors qu'il a appris à générer 50 étapes avec 5 vérifications intermédiaires. R1 a appris que les problèmes complexes nécessitent une pensée complexe - et vos exemples bien intentionnés le limite et lui disent en fait : "Ne sois pas trop intelligent."
Ici se cache une décision cruciale : DeepSeek-R1 n'évalue PAS la qualité du raisonnement, seulement son résultat. Pourquoi cette austérité ? Trois raisons majeures :
1. Éviter le "Reward Hacking"
Si on récompensait les explications "élégantes" ou "claires", le modèle apprendrait rapidement à produire des raisonnements qui sonnent bien plutôt que des raisonnements qui sont bons.
"La fin justifie les moyens" devient littéralement la philosophie d'entraînement.
2. Objectivité Maximale
En maths et en code, une réponse est vraie ou fausse, point final. Introduire des jugements subjectifs sur la qualité du raisonnement ouvrirait la porte aux biais humains.
3. Stimuler la Diversité Cognitive
En ne jugeant que le résultat, on permet au modèle d'explorer des chemins de raisonnement non conventionnels, potentiellement supérieurs aux approches humaines standards.
Ce qui est VOLONTAIREMENT ignoré :
La clarté des explications
L'élégance de la solution
La concision du raisonnement
La justesse des étapes intermédiaires
La "beauté" mathématique
L'Émergence du "Think" : Un Dialogue Interne Inattendu
Le modèle a découvert ensuite par lui-même qu'il devait réfléchir avant de répondre. Et pas juste un peu - profondément, longuement, avec des allers-retours. Il a dès lors spontanément adopté une structure en deux parties :
<think>
[Des centaines, voire milliers de tokens de réflexion]
[Auto-vérifications, retours en arrière, explorations d'alternatives]
</think>
<answer>
[La réponse finale, concise et vérifiée]
</answer>
Le plus remarquable ? Ce pattern n'a jamais été enseigné. Il a émergé naturellement de l'entraînement par renforcement.
Pourquoi le "Think" est DIFFÉRENT des prompts de raisonnement standards
Dans les LLMs standards (CoT prompting) :
"Pensons étape par étape :
1. Étape 1
2. Étape 2
3. Étape 3
Donc réponse = X"
Problèmes :
Linéaire : Pas de retours en arrière
Finalisé : Chaque étape semble définitive
Public : Tout est destiné à être lu
Dans DeepSeek-R1 :
<think>
"Bon, par où commencer ?
Essai 1 : [calculs]... non, erreur de signe.
Essai 2 : [nouvelle approche]... mieux.
Attends, mais si je... [exploration alternative]
Ok, je pense avoir compris. Vérifions : [auto-test]
Oui, ça tient la route.
</think>
<answer>42</answer>
Avantages :
Non-linéaire : Autorise les boucles, retours
Tentatives multiples : Peut abandonner des pistes
Brut : Inclut les doutes, hésitations
Séparation claire : Pensée vs conclusion
Comparaison avec les approches humaines
Humain expert :
Brouillon : Gribouillis, essais, ratures
Solution finale : Propre, structurée
Processus : Non-linéaire, avec retours
LLM standard :
Direct : Passe du problème à la réponse
Linéaire : Une seule passe
Public : Tout est présentable
DeepSeek-R1 :
Brouillon : <think> (privé, désordonné)
Final : <answer> (public, propre)
Processus : Itératif, réflexif
Des Performances Qui Parlent d'Elles-Mêmes
Les résultats sont spectaculaires :
AIME 2024 (compétition mathématique pour lycéens) : 79.8% de réussite
Codeforces : Surclasse 96.3% des programmeurs humains
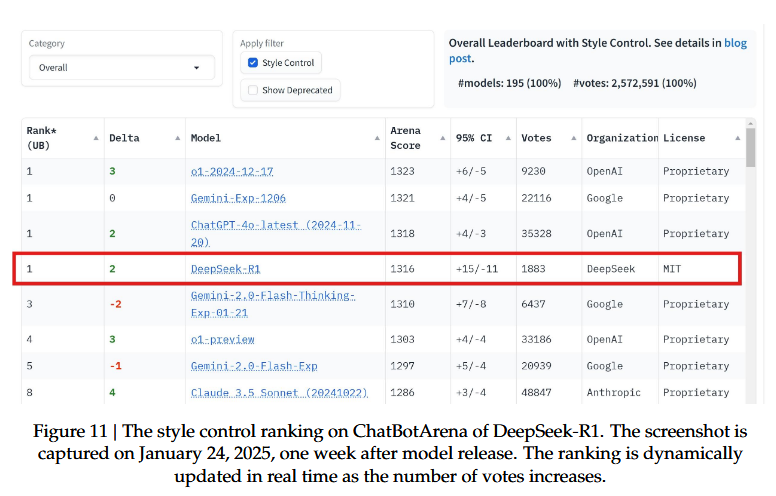
Classement ChatbotArena : Premier ex-aequo avec GPT-4o
Le plus impressionnant ? Ces performances viennent d'un modèle open-source sous licence MIT, avec des versions distillées à partir de seulement 1.5 milliard de paramètres.
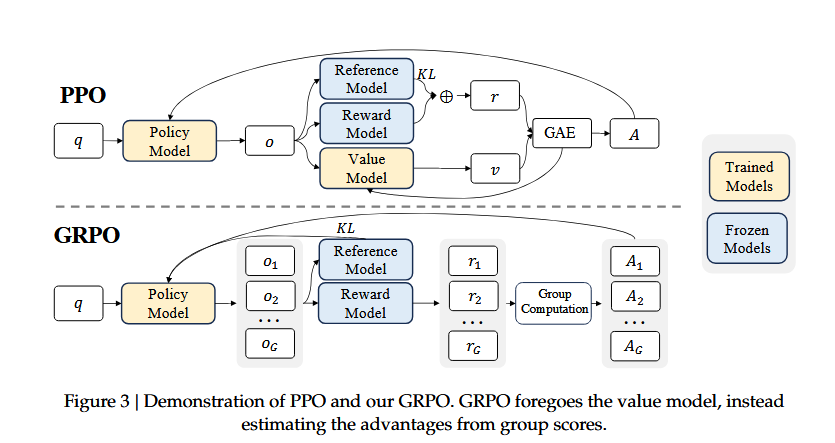
GRPO : Le Moteur Caché
Derrière ces résultats se trouve une innovation algorithmique : GRPO (Group Relative Policy Optimization).
Contrairement au PPO traditionnel qui nécessite un "modèle de valeur" complexe, GRPO fonctionne sur un principe simple : comparer les performances au sein d'un groupe de réponses. Plus élégant, plus stable, plus efficace pour les raisonnements longs.
La Question de la Sécurité
"Un modèle qui raisonne si bien ne pourrait-il pas être dangereux ?"
L'équipe DeepSeek y a pensé. R1 intègre :
Un système de contrôle des risques basé sur DeepSeek-V3
Des évaluations de sécurité multilingues (50 langues)
Des performances comparables aux modèles commerciaux
Les Catégories couvertes par la sécurité :
Contenu dangereux / illégal
Biais et discrimination
Violations de vie privée
Conseils médicaux non vérifiés
Incitation à l'automutilation
Si Vous Utilisez R1 :
Évitez les exemples - laissez-le explorer librement
Privilégiez le zero-shot avec format clair
Faites-lui confiance - il a appris que réfléchir longtemps paie
DeepSeek-R1 n'est pas juste un autre modèle. C'est une démonstration conceptuelle :
L'IA peut développer des stratégies cognitives autonomes
Moins de guidance humaine = plus de créativité computationnelle
L'open-source peut rivaliser avec les géants commerciaux
Nous avons longtemps cru qu'il fallait enseigner aux IA comment raisonner. DeepSeek-R1 nous montre qu'il suffit parfois de créer les conditions pour qu'elles l'apprennent par elles-mêmes. La prochaine frontière ? Des systèmes qui non seulement raisonnent mieux que nous, mais raisonnent différemment - découvrant des chemins cognitifs que nous n'avions même pas imaginés.
Le futur du raisonnement artificiel ne sera pas une imitation, mais une invention.